Here's the thing about PII detection: regex alone isn't enough. And cloud services? They're expensive and require your data to leave your database.
We built something different. Most teams face an uncomfortable choice when it comes to detecting sensitive data.
Your first option: Ship your data to AWS Macie or Google Cloud DLP. That's $500-1,000 per million records. Your data leaves your database. Every. Single. Scan.
Your second option: Write regex patterns yourself. Fast and free—until "Smith Street" gets flagged as a person's name, and your compliance team starts asking questions about false positive rates.
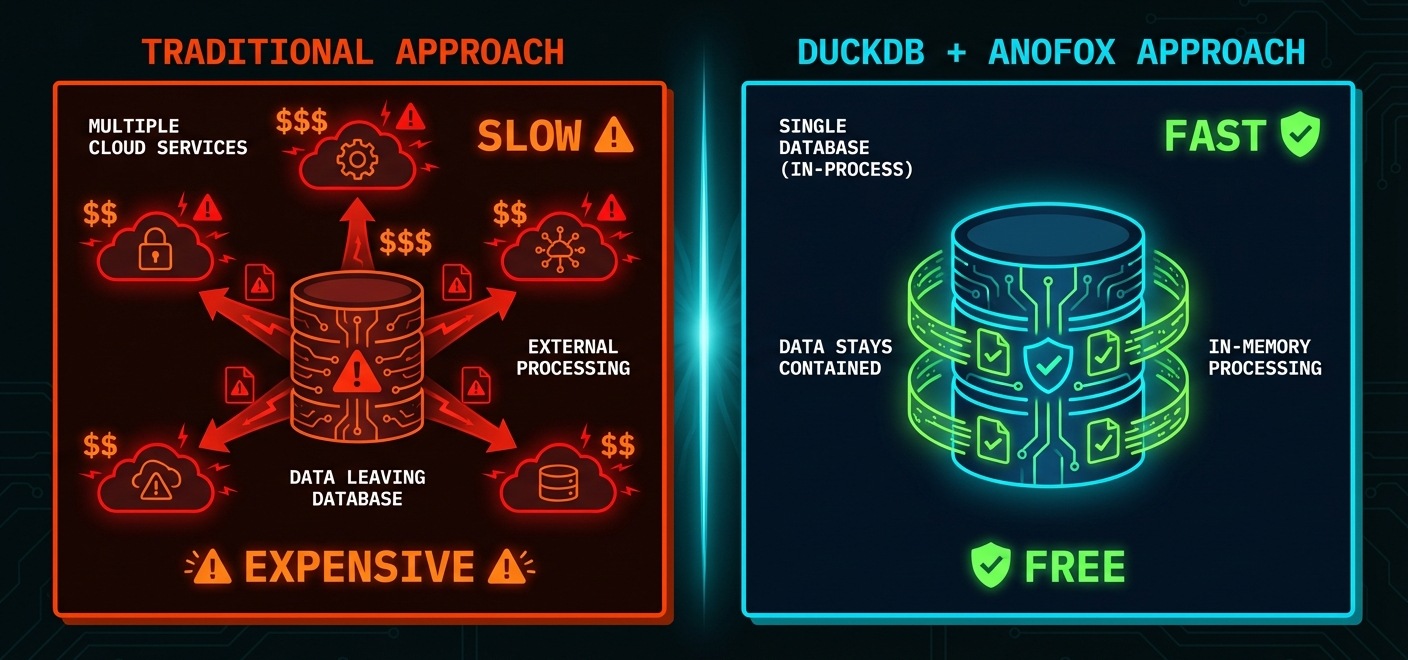
We wanted something better. PII detection that runs inside DuckDB. Zero cost per scan. Data never leaves. And actually understands context.
Two Engines Are Better Than One
Here's what we discovered while building anofox-tabular: neither approach works alone.
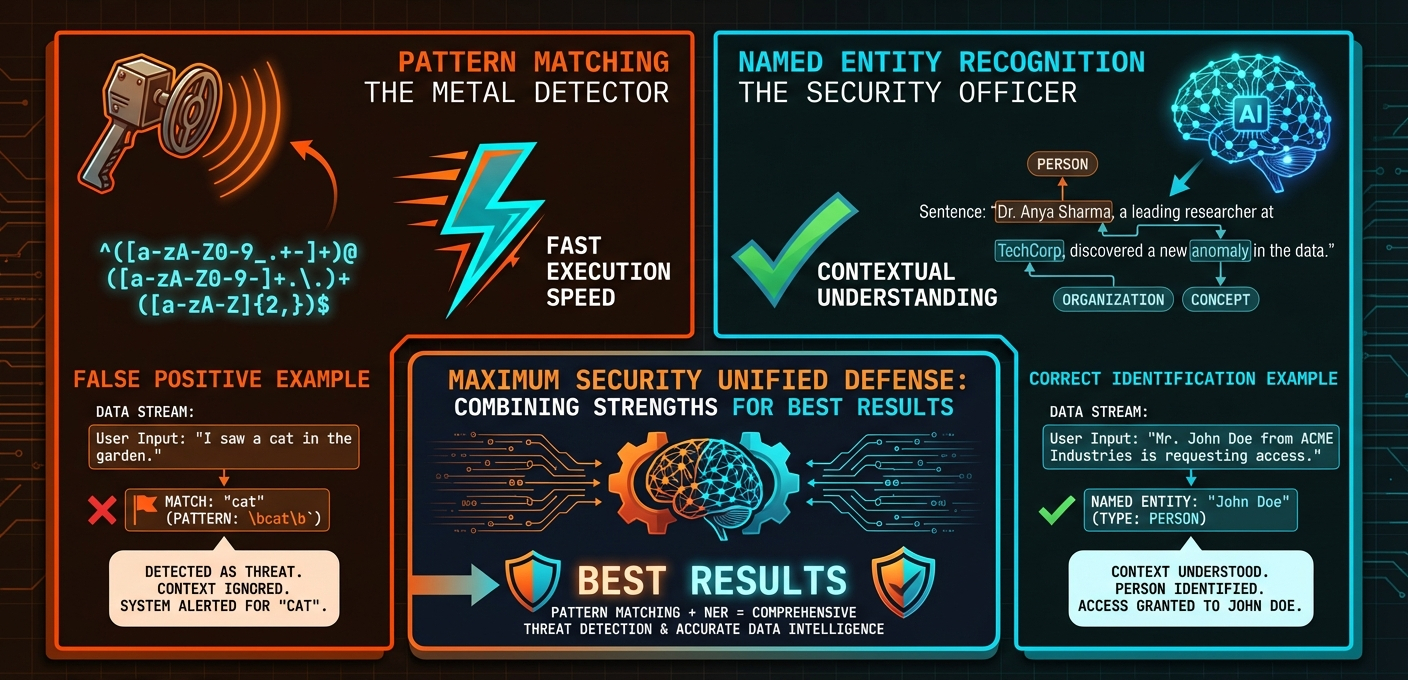
Pattern matching
Pattern matching is fast—microseconds per record. It catches structured PII with mathematical validation: credit cards verified by Luhn checksums, IBANs checked against MOD-97, SSNs validated for format and range. No false positives from random digit sequences.
Unfortunately, pattern matching is blind to context. It doesn't know "John" is sometimes a person and sometimes a place.
Named Entity Recognition (NER)
solves this. We use DistilBERT via OpenVINO—running locally, no cloud API required. The model understands that "John Smith" is a person but "Smith Street" is a location. See:

Same word. Different classification. That's context-awareness in action.
For best results, combine both engines, and each catches what the other misses.
What This Actually Looks Like
Theory is nice. Let's see it work on real data.
Here's a support ticket from a hypothetical customer database:
"Customer Sarah Chen (sarah@company.com) called from (415) 555-0123
about fraudulent charge on 2024-01-15. Address: San Francisco, CA 94102."
Pattern matching finds: EMAIL, PHONE—the structured stuff with clear formats.
NER finds: NAME (Sarah Chen), LOCATION (San Francisco, CA)—the contextual stuff that requires understanding language.
False positives avoided: 2024-01-15 is a date, not an SSN. 94102 is a ZIP code, not a partial card number. A naive regex would flag both.
Pattern matching runs at ~1ms per KB. NER adds ~10ms per KB for contextual analysis. Both run locally with no network overhead. For most tables, you won't notice the difference.
The SQL Functions
We've wrapped this into three functions. Here's how they work.
Detect PII

pii_detect() scans text and returns JSON with each detection: the PII type, the matched text, and a confidence score. Pattern matches with validation get 1.0 confidence. NER detections score lower based on model certainty.
Scan Entire Tables
SELECT * FROM pii_scan_table('customer_support_tickets');
This one's particularly useful during audits. It returns PII counts per column, types found, and sample values. Run it on a new dataset before you start working with it—you might be surprised what's hiding in there.
Mask Sensitive Data
SELECT pii_mask(notes, 'redact') FROM customer_support_tickets;
Four strategies depending on your use case: redact for dashboards and reports, partial when debugging, asterisk for logs, and hash when you need to preserve joins for ML training while hiding actual values.
Try It Yourself
INSTALL anofox_tabular FROM community;
LOAD anofox_tabular;
SELECT pii_detect('Email sarah@company.com or call (415) 555-0123');
SELECT * FROM pii_scan_table('your_table_name');
SELECT pii_mask('Contact john@example.com', 'redact');
In this series:
- SQL-Native PII Detection — What it does and how it works
- Building Privacy-Aware Pipelines — How to integrate it into production
All of this runs in SQL. No external services, no data movement, no per-record costs. Just queries.
Reference Documentation
📖 Full PII Detection Reference →
